
GitHub
The code for the herein described process can also be freely downloaded from https://github.com/majvdvel/meteorites.
Meteorite sightings
Rogue NASA has opened their database to the world at https://data.nasa.gov/, where they demonstrate their own test data and various measurements around the globe. One of the available datasets (which can be downloaded from this location) contains data on over 45 000 meteorites, including their chemical composition, their mass, and the year they were discovered and the corresponding location. Some interesting geospatial visualisations and insights can be obtained from this database, so let’s get going.
For the following workflow, the following packages are used: readr, data.table, lubridate, leaflet, leaflet.extras and maps.
Data collection and cleanup
After downloading the csv file from NASA’s database, the first steps in our analysis process consist of cleaning the data. We use the readr::read_csv() function to load our data into our R instance, and subsequently transform the resulting data.frame into a data.table object, where all NA values are omitted from the table, as they will not benefit us.
met <- read_csv('meteorites/Meteorite_Landings.csv')
met <- na.omit(as.data.table(met))If we now examine the data, we get a nice table. Thanks to NASA’s formatting, we should not have a lot of cleaning to do! We can then use the str() function to check whether every column has its correct class. Since we are only interested in the column types, we will keep the maximum nesting level at 1. Some errors may occur in these types, since readr::read_csv() does not know by default what data types it will extract from the given csv file.
| name | id | nametype | recclass | mass (g) | fall | year | reclat | reclong | GeoLocation |
|---|---|---|---|---|---|---|---|---|---|
| Aachen | 1 | Valid | L5 | 21 | Fell | 01/01/1880 12:00:00 AM | 50.77500 | 6.08333 | (50.775, 6.08333) |
| Aarhus | 2 | Valid | H6 | 720 | Fell | 01/01/1951 12:00:00 AM | 56.18333 | 10.23333 | (56.18333, 10.23333) |
| Abee | 6 | Valid | EH4 | 107000 | Fell | 01/01/1952 12:00:00 AM | 54.21667 | -113.00000 | (54.21667, -113.0) |
| Acapulco | 10 | Valid | Acapulcoite | 1914 | Fell | 01/01/1976 12:00:00 AM | 16.88333 | -99.90000 | (16.88333, -99.9) |
| Achiras | 370 | Valid | L6 | 780 | Fell | 01/01/1902 12:00:00 AM | -33.16667 | -64.95000 | (-33.16667, -64.95) |
| Adhi Kot | 379 | Valid | EH4 | 4239 | Fell | 01/01/1919 12:00:00 AM | 32.10000 | 71.80000 | (32.1, 71.8) |
str(met, max.level = 1)## Classes 'data.table' and 'data.frame': 38115 obs. of 10 variables:
## $ name : chr "Aachen" "Aarhus" "Abee" "Acapulco" ...
## $ id : int 1 2 6 10 370 379 390 392 398 417 ...
## $ nametype : chr "Valid" "Valid" "Valid" "Valid" ...
## $ recclass : chr "L5" "H6" "EH4" "Acapulcoite" ...
## $ mass (g) : num 21 720 107000 1914 780 ...
## $ fall : chr "Fell" "Fell" "Fell" "Fell" ...
## $ year : chr "01/01/1880 12:00:00 AM" "01/01/1951 12:00:00 AM" "01/01/1952 12:00:00 AM" "01/01/1976 12:00:00 AM" ...
## $ reclat : num 50.8 56.2 54.2 16.9 -33.2 ...
## $ reclong : num 6.08 10.23 -113 -99.9 -64.95 ...
## $ GeoLocation: chr "(50.775, 6.08333)" "(56.18333, 10.23333)" "(54.21667, -113.0)" "(16.88333, -99.9)" ...
## - attr(*, "spec")=List of 2
## ..- attr(*, "class")= chr "col_spec"
## - attr(*, ".internal.selfref")=<externalptr>We see that the year column has been interpreted as the character class, and that every year has been presented by the date of its first day. We would very much like to extract the year from these character strings, since the rest of the information is parasitic. For this purpose, we can use the lubridate package. As a first step, the character string gets transformed into a datetime format, which is then entered in the lubridate::year() function to extract the year. For the cases where this procedure fails, an NA value will be introduced, which we can subsequently remove using na.omit().
Another aspect which we can adapt is the fall column. We know from NASA’s documentation that this column contains the distinction between meteorites that have been seen falling, and those who were just found. Consequently, this column only contains the respective entries “Fell” and “Found”. To speed up our future analysis process, we can transform the fall column into a factor column.
Another step which we can take is to change the name of the current mass (g) column into mass. This is purely preferential and will only have an impact on user efficiency.
met[, year := lubridate::dmy_hms(year)]
met[, year := lubridate::year(year)]
met <- na.omit(met)
met[, fall := as.factor(fall)]
setnames(met, 'mass (g)', 'mass')We can now move to the next step of our cleaning procedure. Now the classes for each column have been correctly set, and we can investigate whether the extreme values in these columns are possible. The columns we can investigate are the year, reclong (longitude) and reclat (latitude) columns. The first should give reasonable values, while the latter should be noted between -180 and +180 degrees, and between -90 and +90 degrees, respectively. We can use a neat little trick using apply() to get the results for all three columns at the same time.
apply(met[, c('year', 'reclong', 'reclat')], 2, min)## year reclong reclat
## 1583.00000 -165.43333 -87.36667apply(met[, c('year', 'reclong', 'reclat')], 2, max)## year reclong reclat
## 2101.00000 178.20000 81.16667We can conclude that the longitude and latitude columns have entries in the correct range, and that there might be some years which are not accurate, being set in the distant future. We will impose a threshold of the year 2016 on the data, considering that this is the year in which the dataset was released. Since we do not know the correct discovery date of these meteorites from the get-go, the best idea to not skew our data would be to remove these entries.
An additional cleaning step we will perform is to get rid of all meteorites at coordinates (0.0, 0.0). The reasoning for this can be found in documentation on the meteorites in this virtual location. These were in fact discovered on Antarctica, however some errors snuck in the data and resulted in the meteorites being classified as found at (0.0, 0.0).
After this final cleaning step, we can call data.table’s .N functionality to see how much rows are still left in the table of meteorites.
met <- met[year <= 2016 & (reclat != 0 | reclong != 0)]
met[, .N]## [1] 31924Global meteorite densities
Now that we have prepared our data for analysis, let us do some quick preliminary visualisations. We will use R’s basic plot() function to get a quick taste of the global location of all meteorites. We will use the fall column to color the plot, to be able to distinguish both the found and the fallen meteorites.
plot(met$reclong, met$reclat, col = met$fall, xlab = 'Longitude', ylab = 'Latitude')
legend(135, 35, unique(met$fall), col=1:length(met$fall), pch=1)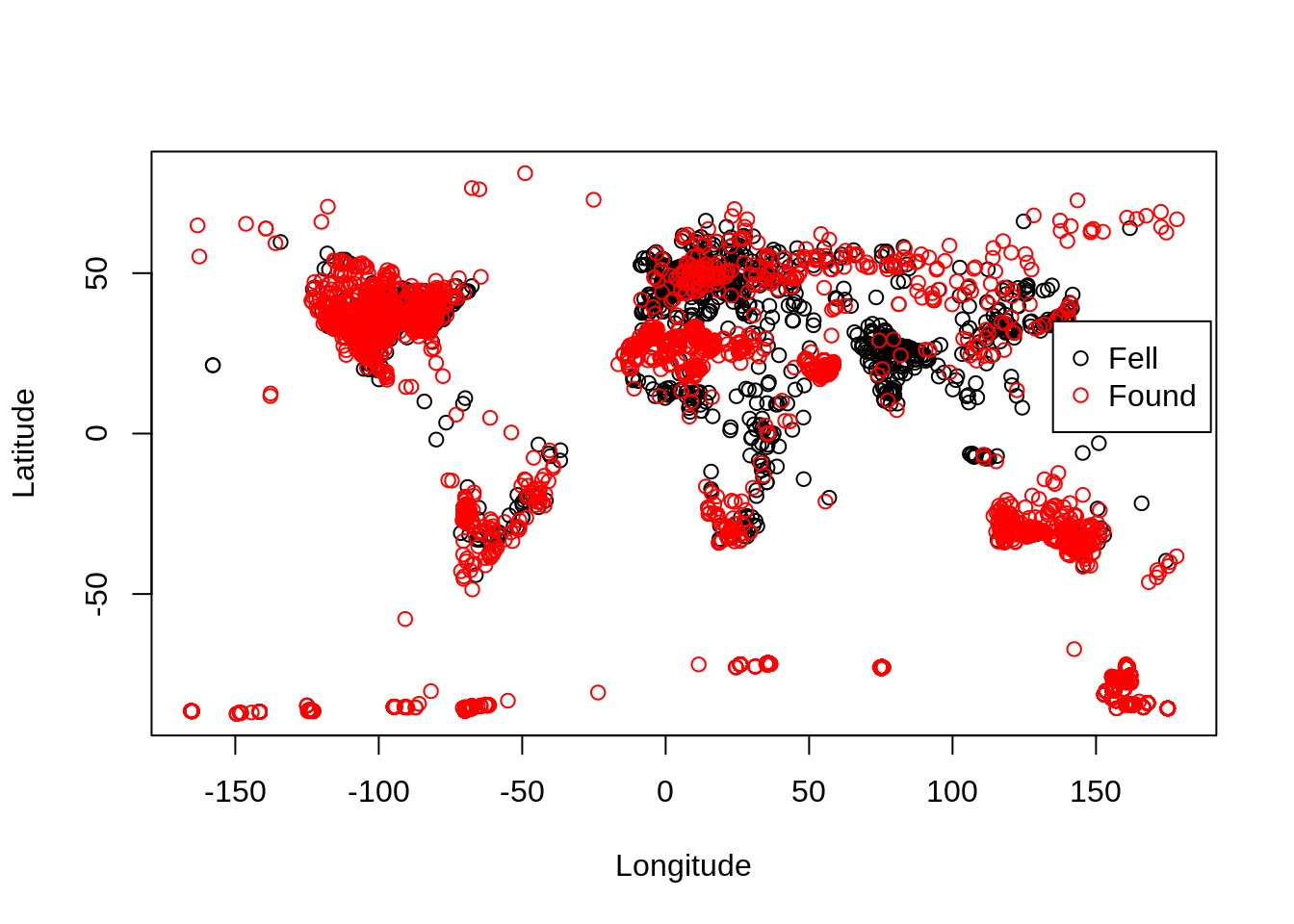
From this very unsofisticated plotting method, we can already make our first (and utmost trivial) conclusion: meteorites have predominantly been found on land.
Clustering with leaflet
While this plot would allow us to reconstruct Earth’s land masses from the locations of these meteorites, a more interesting approach would be to find out where exactly these meteorites have struck. This can be done through an interactive leaflet map, where we will display the meteorite’s location through clustered markers. Upon zooming in on the map, each cluster splits in separate sub-clusters until the individual markers are visible. Note that if no clusterOptions are defined, all 31 924 meteorites will be plotted as a separate marker, which will gravely incapacitate the leaflet’s performance.
We will also add each meteorite’s data to the popup when a marker is clicked.
leaflet(width = '100%') %>% addProviderTiles('CartoDB.Positron') %>%
addMarkers(data = met,
lng = ~reclong, lat = ~reclat,
popup = ~paste('Name:', name, '<br/>',
'Discovered:', year, '<br/>',
'Composition:', recclass, '<br/>',
'Mass:', mass, ' g<br/>'),
clusterOptions = markerClusterOptions())While the clusters provide a fast way to plot the data on a world map, it fails at giving a clear general overview of all meteorites’ locations. We would like to obtain a combination of the first plot, where all points are displayed separately, and the second plot, where we can get more information about the density of the markers.
Doing the leaflet.extras step
An option presents itself as the addHeatmap() function in the leaflet.extras package. Using this tool, we can create a nice and quick overview of our data. Nevertheless, it tends to give worse results than the clustering approach if we want to look very closely at a limited number of locations. Considering this fact, one can argue that a dynamic leaflet plot is not entirely necessary, and a static plotting method using packages like tmap or ggplot2 can be used instead.
leaflet(width = '100%') %>% addProviderTiles('CartoDB.Positron') %>%
addHeatmap(data = met, lng = ~reclong, lat = ~reclat, blur = 25, radius = 10)Where meteorites go to die
We expect meteorites to be able to strike in any place on Earth. Obviously, all meteorites impeding on the ocean will be near impossible to find, which means that we can reduce this first assumption to “we expect meteorites to be found in any place on land”. If we check this statement according to the given heatmap, it is clear that some places, like northern Russia, clearly display a lack of meteorites, while Oman and Antarctica seem to have an abundance of extra-terrestrial rocks lying around. Let us therefore look more closely into the matter and split the set of meteorites in the “Found” and “Fell” categories.
We can start by looking to the large amount of meteorites found in Oman and Antarctica. To get data for each of these entries, let us create a new country column, which uses the longitude and latitude to deduct the corresponding country for every meteorite. We can do this by using the function maps::map.where(). Since some countries are split in the format Country:part, we will omit every part from these names, such that we end up with just the country name. We can subsequently investigate the amounts by using data.table’s .N functionality (and let us ignore that Antarctica is not actually a country):
met[, country := map.where(database = 'world', reclong, reclat)]
met[, country := tstrsplit(country, ':')[1]]
counts <- met[country %in% c('Oman', 'Antarctica'), .N, by = c('country', 'fall')]We obtain the following table for the meteorite counts:
| country | fall | N |
|---|---|---|
| Antarctica | Found | 20159 |
| Oman | Found | 2992 |
We can see that no meteorites have been seen falling, while over 20 000 and nearly 3000 meteorites have been found in Antarctica and Oman, respectively. If we do some research on these matters, we find that the reason for these high numbers are the meteorite searching expeditions which are organised in Oman and Antarctica because of the contrasting properties of the underlying sand and ice, which facilitates finding meteorites.
Following the same procedure, we find that in total about 1000 meteorites were seen falling globally, while over 30000 were found without previous sightings. Note that this considers only the filtered data, and some results might be lost in the meteorites with bad table entries. Considering that not all areas are equally suited for meteorite searches, a clear example for this is northern Russia, which is sparsely populated and provides too many contrasting elements to clearly distinguish a meteorite from its surroundings.
If a meteorite falls in a forest…
If we think about the meteorite sightings, we wonder if there is a correlation to the local population density. It will be hard to significantly compare actual population density to meteorite density since there are only around 1000 meteorites sighted, but there is sufficient data to give a first impression. Since we are not going to delve into full scientific proof, we can take some small artistic freedom to provide a nice data visualisation.
As you may know, leaflet operates with a geographical tiles system. Besides the standard tiles provided by OpenStreetMap and the popular CartoDB tiles, NASA has also provided some tiles which prove to be interesting for our current visualisation. We will use the NASAGIBS.ViirsEarthAtNight2012 tiles. While I do not want to spoil the surprise, some information can be deducted from the name. We will now plot the meteorites where the fall category equals “Fell”, again with the leaflet.extras::addHeatmap() function.
leaflet(width = '100%') %>%
setView(lng = 10, lat = 20, zoom = 2) %>%
addProviderTiles(providers$NASAGIBS.ViirsEarthAtNight2012, options = providerTileOptions(minZoom = 2)) %>%
addHeatmap(data = met[fall == 'Fell'], lng = ~reclong, lat = ~reclat, blur = 25, radius = 10)Conclusions
In a nightly view of Earth, one can deduct from present lighting the presence of population. We see on this image, that for places with more light, and thus arguably a lot of population, more meteorites have been seen falling. It has to be noted however that areas with less light are not necessarily more sparsely populated, however some link may be present, but development factors have to be taken into account as well. While this image therefore does not prove correlation between population density and meteorite sighting density, there clearly is a link between the presence of population and sightings of meteorites.